
A Weird Incident With Aurora: A Boot Loop
On March 15th, we had a two-hour platform-wide outage caused by a database anomaly. The story goes back to two weeks before, on March 3rd, when we upgraded from Aurora version 2 (MySQL 5.7) to Aurora version 3 (MySQL 8). As soon as we upgraded, we noticed an increase in commit latency on our writers (figure below).
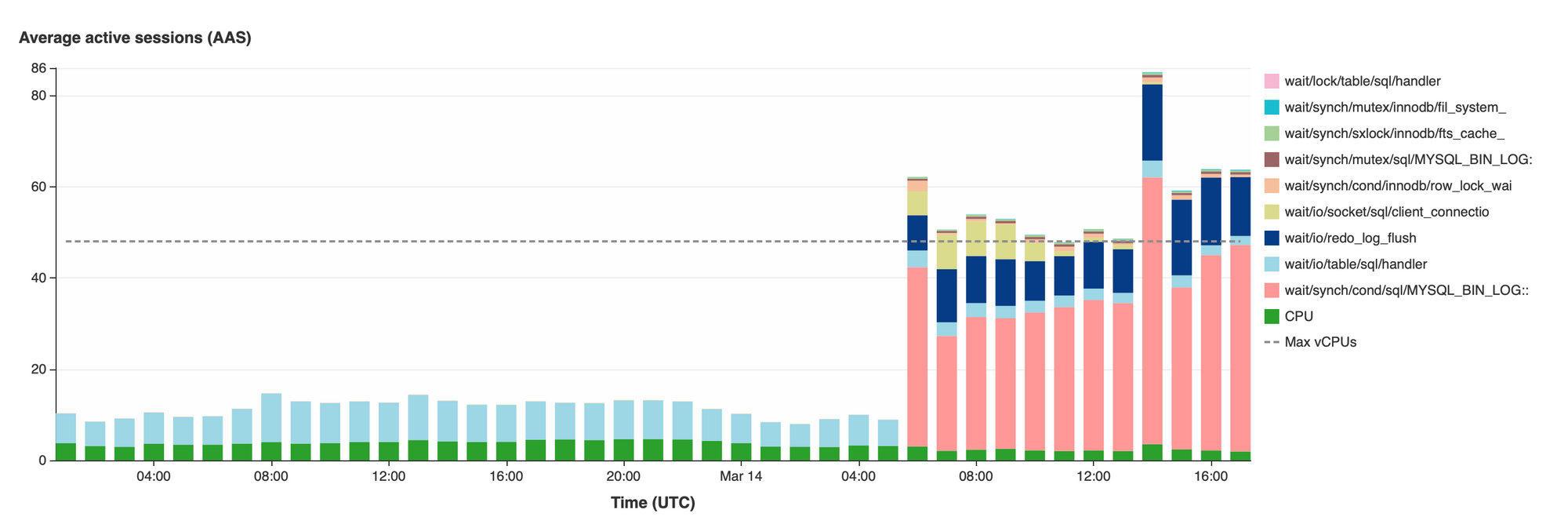
Notice the light-red-ish bar corresponding to MYSQL_BIN_LOG and how it increased after the upgrade from virtually non-existent to taking most of an active session's time. Binlogs, for the uninitiated, contain a list of all the events that happened on the database, like inserts, updates, alters, and so on. These logs are used for replication in a few ways. However, in Amazon Aurora, replication happens through the cluster volumes rather than binlogs, meaning that by default, binlogs are unneeded and disabled. However, in our case, we need binlogs to replicate to our data warehouse.
After Amazon's support on a few tickets, it turns out the binlog commit characteristics have changed between Aurora version 2 and version 3, leading to higher latencies in committing binlogs. Their first recommendation was to group our queries in transactions so that we minimize commits, reducing disk I/O and potentially improving the overall latency. Following this recommendation and grouping a few of our big jobs into transactions to reduce commits, we saw little to no improvement in latency. However, understanding this change is crucial to understanding the outage.
A few days later, on March 7th, we were able to sustain a higher load, but the commit latency was still high, which led us to disable binlogs to avoid outages during our high season. The problem is we got stuck without data replication to the data warehouse.
So, on the 14th at 8 AM, we decided to enable binlogs again to replicate data to our warehouse. Things were fine until 8 PM; we started to see a spike in latency, causing performance degradation across the platform. At 8:20 PM, we created a larger instance (16xlarge) to mitigate the issue and then disabled binlogs. Disabling binlogs requires a restart, so we did ... and we're down. The new instance got stuck in rebooting state for 20 minutes until we realized that the database kept restarting every 5 minutes. We opened a ticket and reached out to our contacts at AWS. We got a quick response, but investigations took a while. After an hour, it turns out Aurora's internal timeout for health checks is about 3 mins, and if that health check fails, Aurora will automatically trigger a reboot. So our instances were stuck in a boot loop due to the health check. But still, the question is, why is it not booting within this timeout? AWS's docs say it should reboot in 1 - 2 minutes.
For an ACID database, if a database is interrupted in the middle of a transaction (say, for a reboot), it would roll back that transaction to avoid getting into a corrupt or inconsistent state. So, what was happening was that there was a running transaction that had not been committed at the moment of the first reboot. And after we reboot, that transaction HAS to be rolled back before the database can operate. This is where our change of grouping more operations in a single transaction to minimize commit comes to bite us. The transaction was so large that it would not roll back in the 3-minute timeout period, so Aurora would just restart the database.
The solution was that AWS's internal service had to go and disable those health checks and give the database more time to roll back the transaction. Unfortunately, there is no option to do that through the console, nor would the logs give you any helpful information about this.
The AWS team helped get down to the problem and fix it, but that was once they received it (even though they have systems constantly monitoring such outages, some things still go unnoticed). The important lesson learned is that we should have proactively opened a support ticket before rebooting or starting a failover – which they had previously suggested we do for big events like these. Further to this, it is important to share that we were one of the first companies to experience the problem with commit latency being way too high, and it is clear that by sharing our experiences, we are all able to jointly improve the services that our partners give to others as well!
Moving forward, we are disabling binlogs and will use other solutions for our data pipelines – a topic for a future post.